… die Grundidee der Runge-Kutta-Verfahren beschreiben können.
… den Unterschied zwischen verschiedenen Ordnungen von Runge-Kutta-Verfahren erklären können.
… das Konzept der Konvergenzordnung erklären können.
… Runge-Kutta-Verfahren zur numerischen Lösung von Differentialgleichungen anwenden können.
… die Funktion scipy.integrate.solve_ivp verstehen und anwenden können.
Einführung
Im vorherigen Kapitel haben wir das Euler-Verfahren als einfachstes numerisches Integrationsverfahren kennengelernt. Seine Herleitung basiert auf der Annahme konstanter Steigung über einen Zeitschritt, was zu einem Verfahren erster Ordnung führt. Um eine akzeptable Genauigkeit zu erreichen, sind daher sehr kleine Zeitschritte erforderlich.
Die Runge-Kutta-Verfahren stellen eine Familie von Integrationsverfahren höherer Ordnung dar, die durch geschickte Kombination mehrerer Funktionsauswertungen pro Zeitschritt eine wesentlich bessere Genauigkeit erzielen. Diese Verfahren bilden die algorithmische Grundlage der meisten modernen Differentialgleichungslöser, einschließlich der Funktion scipy.integrate.solve_ivp.
Die zentrale Idee besteht darin, die Steigung der Lösungskurve nicht nur am Anfang des Intervalls auszuwerten, sondern auch an weiteren Zwischenpunkten. Durch geeignete Gewichtung dieser Steigungswerte lässt sich der Fehler systematisch reduzieren, ohne dass Ableitungen höherer Ordnung berechnet werden müssen.
Das Euler-Verfahren als Ausgangspunkt
Betrachten wir erneut das Anfangswertproblem \[
\frac{\mathrm{d}\mathbf{y}}{\mathrm{d}t} = \mathbf{g}(\mathbf{y}, t), \quad \mathbf{y}(t_0) = \mathbf{y}_0.
\tag{1}\]
Das explizite Euler-Verfahren approximiert die Lösung zum Zeitpunkt \(t + \Delta t\) durch \[
\mathbf{y}(t + \Delta t) = \mathbf{y}(t) + \Delta t \, \mathbf{g}(\mathbf{y}(t), t) + \mathcal{O}(\Delta t^2).
\tag{2}\]
Der Fehlerterm \(\mathcal{O}(\Delta t^2)\) bezeichnet den lokalen Abbruchfehler, also den Fehler, der in einem einzelnen Zeitschritt entsteht. Da für eine Integration über die Zeit \(T\) insgesamt \(N = T/\Delta t\) Schritte benötigt werden, akkumuliert sich dieser lokale Fehler zum globalen Fehler \(\mathcal{O}(\Delta t)\).
NoteKonvergenzordnung
Ein numerisches Verfahren besitzt die Konvergenzordnung \(p\), wenn der globale Fehler wie \(\mathcal{O}(\Delta t^p)\) mit dem Zeitschritt skaliert. Das Euler-Verfahren hat demnach Konvergenzordnung 1. Ein Verfahren der Ordnung \(p\) hat einen lokalen Abbruchfehler von \(\mathcal{O}(\Delta t^{p+1})\).
Das Heun-Verfahren
Die fundamentale Schwäche des Euler-Verfahrens liegt darin, dass es nur die Steigung am Anfang des Intervalls verwendet. Eine bessere Approximation würde die durchschnittliche Steigung über das gesamte Intervall berücksichtigen. Da die Steigung am Ende des Intervalls jedoch von der noch unbekannten Lösung \(\mathbf{y}(t + \Delta t)\) abhängt, muss sie zunächst geschätzt werden.
Das Heun-Verfahren, auch als Prädiktor-Korrektor-Verfahren bekannt, realisiert diese Idee in zwei Schritten. Im ersten Schritt, dem Prädiktor, wird ein vorläufiger Schätzwert für die Lösung am Ende des Intervalls berechnet: \[
\tilde{\mathbf{y}}(t + \Delta t) = \mathbf{y}(t) + \Delta t \, \mathbf{g}(\mathbf{y}(t), t).
\tag{3}\]
Im zweiten Schritt, dem Korrektor, wird die Lösung unter Verwendung des Mittelwerts der Steigungen am Anfang und am geschätzten Ende des Intervalls neu berechnet: \[
\mathbf{y}(t + \Delta t) = \mathbf{y}(t) + \frac{\Delta t}{2} \left[ \mathbf{g}(\mathbf{y}(t), t) + \mathbf{g}(\tilde{\mathbf{y}}(t + \Delta t), t + \Delta t) \right].
\tag{4}\]
Das Heun-Verfahren erreicht die Konvergenzordnung 2, was bedeutet, dass eine Halbierung des Zeitschritts den Fehler um den Faktor 4 reduziert. Im Vergleich dazu würde das Euler-Verfahren bei Halbierung des Zeitschritts den Fehler nur halbieren.
NoteHerleitung der Konvergenzordnung
Um die Ordnung des Heun-Verfahrens zu bestimmen, vergleichen wir es mit der Taylor-Entwicklung der exakten Lösung. Für eine skalare Gleichung \(y' = g(y, t)\) gilt: \[
y(t + \Delta t) = y(t) + \Delta t \, y'(t) + \frac{\Delta t^2}{2} y''(t) + \mathcal{O}(\Delta t^3).
\]
Mit \(y' = g\) und der Kettenregel folgt für die zweite Ableitung: \[
y'' = \frac{\mathrm{d}g}{\mathrm{d}t} = \frac{\partial g}{\partial y} y' + \frac{\partial g}{\partial t} = g \frac{\partial g}{\partial y} + \frac{\partial g}{\partial t}.
\]
Damit lautet die exakte Lösung: \[
y(t + \Delta t) = y + \Delta t \, g + \frac{\Delta t^2}{2} \left( g \frac{\partial g}{\partial y} + \frac{\partial g}{\partial t} \right) + \mathcal{O}(\Delta t^3).
\tag{5}\]
Für das Heun-Verfahren entwickeln wir \(g(\tilde{y}, t + \Delta t)\) mit \(\tilde{y} = y + \Delta t \, g\): \[
g(\tilde{y}, t + \Delta t) = g(y, t) + \Delta t \, g \frac{\partial g}{\partial y} + \Delta t \frac{\partial g}{\partial t} + \mathcal{O}(\Delta t^2).
\]
Einsetzen in die Korrektor-Formel (Gleichung 4) ergibt: \[
\begin{aligned}
y_{i+1} &= y + \frac{\Delta t}{2} \left[ g + g + \Delta t \left( g \frac{\partial g}{\partial y} + \frac{\partial g}{\partial t} \right) + \mathcal{O}(\Delta t^2) \right] \\
&= y + \Delta t \, g + \frac{\Delta t^2}{2} \left( g \frac{\partial g}{\partial y} + \frac{\partial g}{\partial t} \right) + \mathcal{O}(\Delta t^3).
\end{aligned}
\tag{6}\]
Der Vergleich von Gleichung 6 mit Gleichung 5 zeigt, dass das Heun-Verfahren die exakte Lösung bis einschließlich \(\mathcal{O}(\Delta t^2)\) reproduziert. Der lokale Abbruchfehler ist daher \(\mathcal{O}(\Delta t^3)\), was einem Verfahren zweiter Ordnung entspricht.
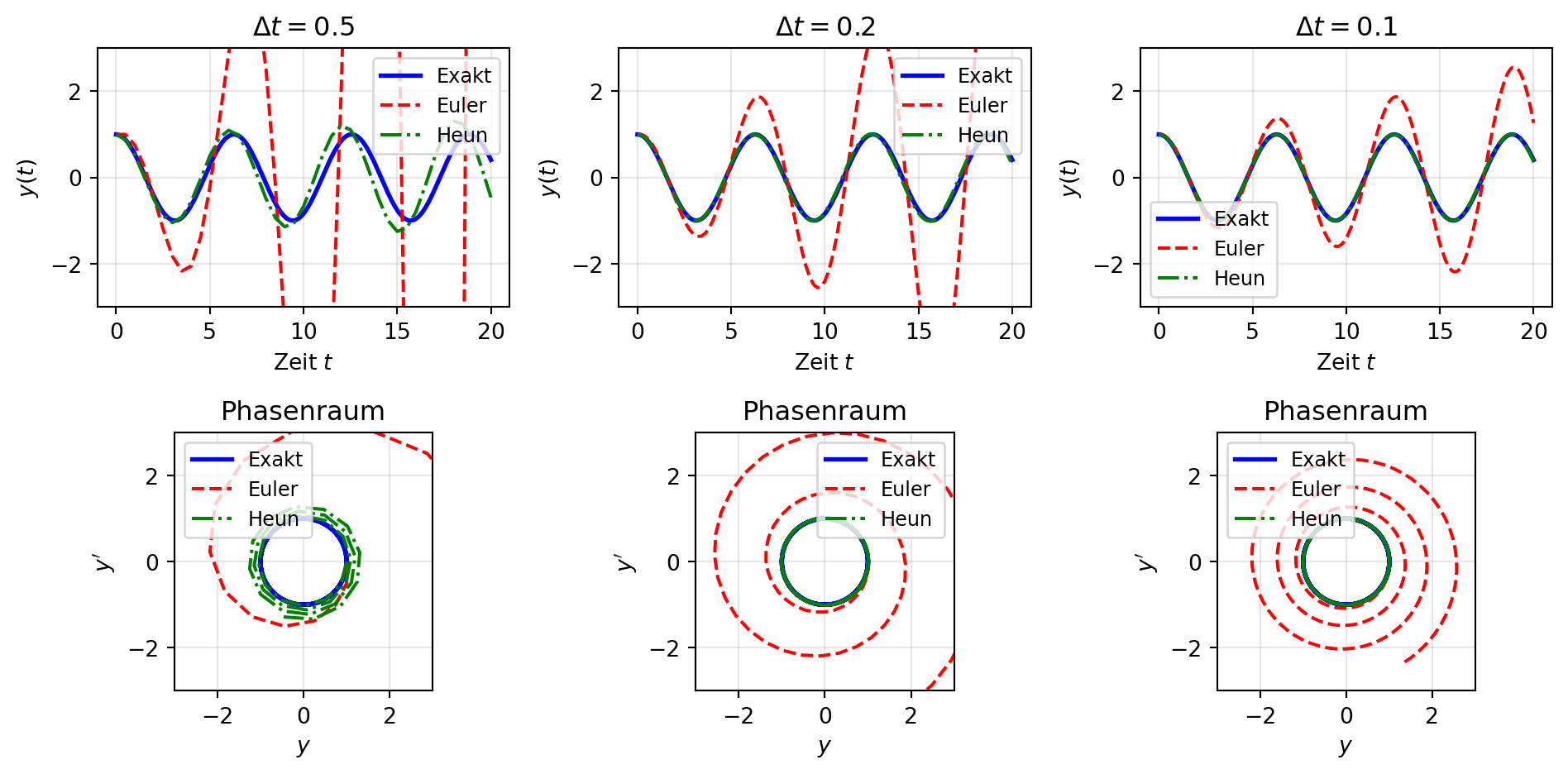
Abbildung 1: Vergleich von Euler- und Heun-Verfahren für den harmonischen Oszillator. Das Heun-Verfahren zeigt bei gleichem Zeitschritt eine deutlich bessere Energieerhaltung als das Euler-Verfahren.
Abbildung 1 verdeutlicht den qualitativen Unterschied zwischen Euler- und Heun-Verfahren am Beispiel des harmonischen Oszillators. In der oberen Reihe zeigt der Zeitverlauf der Lösung, dass das Euler-Verfahren bei größeren Zeitschritten eine wachsende Amplitude aufweist, während das Heun-Verfahren die Schwingung wesentlich besser erhält. Die untere Reihe zeigt das Verhalten im Phasenraum, wo die exakte Lösung einem Kreis entspricht. Das Euler-Verfahren spiralt nach außen, was die künstliche Energiezufuhr widerspiegelt, während das Heun-Verfahren dem Kreis deutlich besser folgt.
NoteVergleich mit dem Leapfrog-Verfahren
Das Heun-Verfahren und das in ?@sec-ch11-leapfrog eingeführte Leapfrog-Verfahren sind beide Verfahren zweiter Ordnung mit Prädiktor-Korrektor-Struktur, unterscheiden sich aber grundlegend in ihrer Konzeption:
Runge-Kutta-Verfahren (wie Heun) sind universelle Integratoren für beliebige Differentialgleichungen erster Ordnung \(\mathbf{y}' = \mathbf{g}(\mathbf{y}, t)\). Sie machen keine Annahmen über die Struktur der Gleichung und sind daher breit einsetzbar.
Das Leapfrog-Verfahren ist ein spezialisierter Integrator für Gleichungen der Form \(\ddot{x} = f(x)\), bei denen die Beschleunigung nur von der Position abhängt. Diese Struktur ist charakteristisch für konservative mechanische Systeme (Hamilton-Systeme).
Der entscheidende Vorteil des Leapfrog-Verfahrens liegt in seiner Symplektizität: Es erhält das Phasenraumvolumen exakt und zeigt daher keine systematische Energiedrift bei Langzeitintegrationen. Das Heun-Verfahren ist nicht symplektisch – wie in Abbildung 1 sichtbar, spiralt auch die Heun-Trajektorie im Phasenraum, wenn auch langsamer als beim Euler-Verfahren.
Für Hamiltonsche Systeme ist daher das Leapfrog-Verfahren oft die bessere Wahl, während Runge-Kutta-Verfahren ihre Stärke bei allgemeinen, nicht-konservativen Problemen ausspielen.
Das klassische Runge-Kutta-Verfahren vierter Ordnung
Das am weitesten verbreitete Runge-Kutta-Verfahren ist das klassische Verfahren vierter Ordnung, das vier Funktionsauswertungen pro Zeitschritt verwendet. Es lässt sich als gewichteter Mittelwert von vier Steigungsschätzungen schreiben: \[
\mathbf{y}_{i+1} = \mathbf{y}_i + \frac{\Delta t}{6} \left[ \mathbf{k}_1 + 2\mathbf{k}_2 + 2\mathbf{k}_3 + \mathbf{k}_4 \right]
\tag{7}\]
Die vier Steigungen werden dabei sequentiell berechnet, wobei jede nachfolgende Steigung auf den vorherigen aufbaut: \[
\begin{aligned}
\mathbf{k}_1 &= \mathbf{g}(\mathbf{y}_i, t_i) \\
\mathbf{k}_2 &= \mathbf{g}\left(\mathbf{y}_i + \frac{\Delta t}{2} \mathbf{k}_1, t_i + \frac{\Delta t}{2}\right) \\
\mathbf{k}_3 &= \mathbf{g}\left(\mathbf{y}_i + \frac{\Delta t}{2} \mathbf{k}_2, t_i + \frac{\Delta t}{2}\right) \\
\mathbf{k}_4 &= \mathbf{g}\left(\mathbf{y}_i + \Delta t \, \mathbf{k}_3, t_i + \Delta t\right)
\end{aligned}
\tag{8}\]
Die erste Steigung \(\mathbf{k}_1\) entspricht der Steigung am Anfang des Intervalls und ist identisch mit der beim Euler-Verfahren verwendeten Steigung. Die zweite Steigung \(\mathbf{k}_2\) wird in der Mitte des Intervalls ausgewertet, wobei die Position durch einen halben Euler-Schritt mit \(\mathbf{k}_1\) geschätzt wird. Die dritte Steigung \(\mathbf{k}_3\) wird ebenfalls in der Mitte des Intervalls berechnet, verwendet aber die verbesserte Positionsschätzung basierend auf \(\mathbf{k}_2\). Schließlich liefert \(\mathbf{k}_4\) die Steigung am Ende des Intervalls unter Verwendung eines vollen Schritts mit \(\mathbf{k}_3\).
Die Gewichte \(1/6\), \(2/6\), \(2/6\) und \(1/6\) in der Kombinationsformel sind nicht willkürlich gewählt, sondern so bestimmt, dass der Fehler optimal minimiert wird. Eine Taylorentwicklung zeigt, dass diese Koeffizienten zu einem lokalen Abbruchfehler von \(\mathcal{O}(\Delta t^5)\) führen, was einem Verfahren vierter Ordnung entspricht.
TipDie Simpson-Regel
Die Gewichtung \((1 + 2 + 2 + 1)/6\) im klassischen RK4-Verfahren ist eng verwandt mit der Simpson-Regel für numerische Integration. Die Simpson-Regel approximiert ein Integral über das Intervall \([a, b]\) durch \[
\int_a^b f(x) \, \mathrm{d}x \approx \frac{b-a}{6} \left[ f(a) + 4 f\left(\frac{a+b}{2}\right) + f(b) \right].
\] Diese Formel gewichtet den Funktionswert in der Mitte des Intervalls vierfach so stark wie die Randwerte, was einer parabolischen Interpolation entspricht. Im RK4-Verfahren tragen die beiden Mittelwerte \(\mathbf{k}_2\) und \(\mathbf{k}_3\) zusammen das Gewicht \(4/6\), während die Randwerte \(\mathbf{k}_1\) und \(\mathbf{k}_4\) je das Gewicht \(1/6\) erhalten. Die Verwendung zweier Mittelpunktschätzungen statt einer einzigen ermöglicht es, den Fehler weiter zu reduzieren.
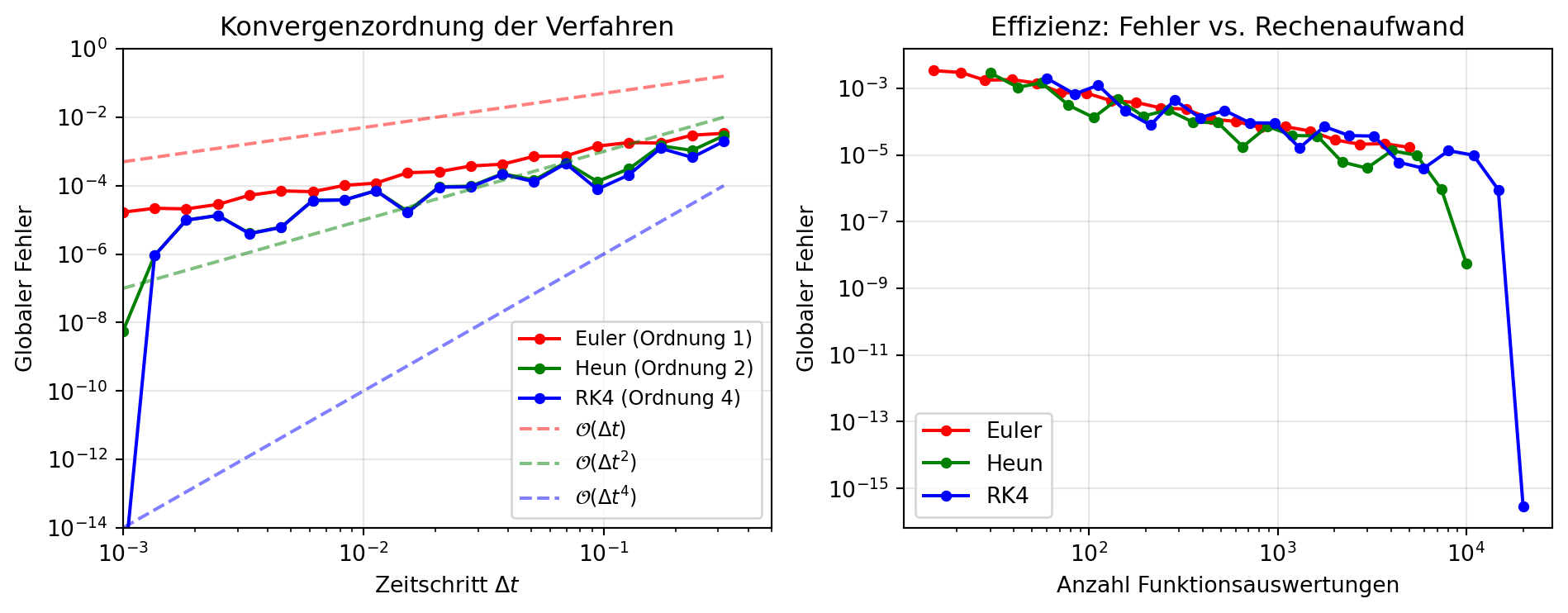
Abbildung 2: Konvergenzverhalten verschiedener Runge-Kutta-Verfahren. Das RK4-Verfahren erreicht bei gleichem Rechenaufwand eine deutlich höhere Genauigkeit als Verfahren niedrigerer Ordnung.
Abbildung 2 quantifiziert die Überlegenheit höherer Ordnungsverfahren. Der linke Teil zeigt die Konvergenzordnung: Der Fehler des Euler-Verfahrens skaliert linear mit \(\Delta t\), der des Heun-Verfahrens quadratisch, und der des RK4-Verfahrens mit der vierten Potenz. Eine Halbierung des Zeitschritts reduziert beim RK4-Verfahren den Fehler um den Faktor 16.
Der rechte Teil betrachtet die Effizienz unter Berücksichtigung des Rechenaufwands. Obwohl das RK4-Verfahren viermal so viele Funktionsauswertungen pro Zeitschritt benötigt wie das Euler-Verfahren, erreicht es bei gleichem Gesamtaufwand eine um Größenordnungen höhere Genauigkeit. Dies macht höherwertige Verfahren in der Praxis nahezu immer vorzuziehen.
Die Funktion solve_ivp
Die Funktion scipy.integrate.solve_ivp stellt eine moderne, robuste Implementierung verschiedener Runge-Kutta-Verfahren mit automatischer Schrittweitenkontrolle bereit. Sie ist der empfohlene Standardweg zur numerischen Lösung gewöhnlicher Differentialgleichungen in Python.
Die verfügbaren Methoden umfassen RK23, ein eingebettetes Runge-Kutta-Verfahren der Ordnung 2 mit Fehlerschätzer der Ordnung 3, das für weniger anspruchsvolle Probleme geeignet ist. Die Standardmethode RK45 ist ein Verfahren der Ordnung 4 mit Fehlerschätzer der Ordnung 5, bekannt als Dormand-Prince-Verfahren. Für Probleme, die höchste Genauigkeit erfordern, steht DOP853 zur Verfügung, ein Verfahren der Ordnung 8 mit eingebetteten Fehlerschätzern der Ordnungen 5 und 3.
Die Notation “4(5)” bedeutet, dass das Verfahren selbst die Ordnung 4 hat, aber einen eingebetteten Fehlerschätzer der Ordnung 5 verwendet. Dieser Fehlerschätzer ermöglicht die automatische Anpassung des Zeitschritts, die im nächsten Kapitel behandelt wird.
Struktur eines solve_ivp-Aufrufs
Die Verwendung von solve_ivp folgt einem einheitlichen Muster. Die zu lösende Differentialgleichung wird als Funktion definiert, die den aktuellen Zeitpunkt und Zustand als Argumente erhält und die Zeitableitung zurückgibt:
from scipy.integrate import solve_ivpdef differentialgleichung(t, y, param1, param2):""" Rechte Seite der DGL dy/dt = f(t, y) WICHTIG: Der Zeitpunkt t ist das erste Argument, der Zustandsvektor y das zweite! """ dydt = ... # Berechne Ableitungenreturn dydtsolution = solve_ivp( differentialgleichung, # Die DGL-Funktion t_span=(t_start, t_end), # Zeitintervall y0=[y1_0, y2_0, ...], # Anfangsbedingungen args=(param1, param2), # Zusätzliche Parameter method='RK45', # Integrationsverfahren t_eval=t_array, # Zeitpunkte für Ausgabe dense_output=True, # Interpolation zwischen Punkten rtol=1e-3, # Relative Toleranz atol=1e-6# Absolute Toleranz)# Zugriff auf die Lösungt = solution.t # Zeitpunktey = solution.y # Lösungswerte (y[0] ist erste Komponente)
ImportantArgumentreihenfolge
Bei solve_ivp lautet die Reihenfolge der Argumente dgl(t, y, ...), also Zeit vor Zustand. Dies unterscheidet sich von manchen älteren Konventionen und der Notation in diesem Skript, wo wir g(y, t) schreiben. Die Wahl von SciPy hat praktische Gründe, da sie das Hinzufügen optionaler Parameter erleichtert.
Beispiel: Der gedämpfte harmonische Oszillator
Als Anwendungsbeispiel betrachten wir den gedämpften harmonischen Oszillator, der durch die Bewegungsgleichung \[
m \ddot{y} + c \dot{y} + k y = 0
\tag{9}\] beschrieben wird. Hierbei bezeichnet \(m\) die Masse, \(c\) die Dämpfungskonstante und \(k\) die Federkonstante.
Dieses System zweiter Ordnung lässt sich durch Einführung der Geschwindigkeit \(v = \dot{y}\) in ein System erster Ordnung umschreiben: \[
\dot{y} = v, \quad \dot{v} = -\frac{c}{m} v - \frac{k}{m} y.
\tag{10}\]
Das Verhalten des Systems hängt vom Verhältnis der Dämpfung zur kritischen Dämpfung \(c_\mathrm{krit} = 2\sqrt{km}\) ab. Für \(c < c_\mathrm{krit}\) schwingt das System gedämpft, für \(c = c_\mathrm{krit}\) liegt der aperiodische Grenzfall vor, und für \(c > c_\mathrm{krit}\) ist das System überdämpft und kriecht ohne Schwingung zum Gleichgewicht zurück.
Code
import numpy as npimport matplotlib.pyplot as pltfrom scipy.integrate import solve_ivpdef damped_oscillator(t, y, m, c, k):""" Gedämpfter harmonischer Oszillator Der Zustandsvektor y = [Position, Geschwindigkeit] beschreibt den momentanen mechanischen Zustand des Systems. """return [y[1], -(c/m)*y[1] - (k/m)*y[0]]# Parameterm =1.0k =4.0# ergibt omega_0 = 2c_values = [0.0, 0.5, 2.0, 4.0]labels = ['Ungedämpft', 'Schwach gedämpft', 'Kritisch gedämpft', 'Stark gedämpft']# Anfangsbedingungen und Zeitintervally0 = [1.0, 0.0]t_span = (0, 10)t_eval = np.linspace(0, 10, 500)fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))colors = ['blue', 'green', 'orange', 'red']for c, label, color inzip(c_values, labels, colors): sol = solve_ivp( damped_oscillator, t_span, y0, args=(m, c, k), method='RK45', t_eval=t_eval, dense_output=True ) ax1.plot(sol.t, sol.y[0], color=color, linewidth=2, label=label) ax2.plot(sol.y[0], sol.y[1], color=color, linewidth=2, label=label)ax1.set_xlabel('Zeit $t$')ax1.set_ylabel('Position $y(t)$')ax1.set_title('Zeitverlauf')ax1.legend()ax1.grid(True, alpha=0.3)ax1.axhline(y=0, color='k', linewidth=0.5)ax2.set_xlabel('Position $y$')ax2.set_ylabel('Geschwindigkeit $\\dot{y}$')ax2.set_title('Phasenraum')ax2.legend()ax2.grid(True, alpha=0.3)ax2.axhline(y=0, color='k', linewidth=0.5)ax2.axvline(x=0, color='k', linewidth=0.5)plt.tight_layout()plt.show()# Ausgabe der Integrationsstatistiksol = solve_ivp(damped_oscillator, t_span, y0, args=(m, 0.5, k), method='RK45')print(f"Schwach gedämpfter Fall (c=0.5):")print(f" Anzahl der Zeitschritte: {len(sol.t)}")print(f" Anzahl der Funktionsauswertungen: {sol.nfev}")print(f" Integration erfolgreich: {sol.success}")
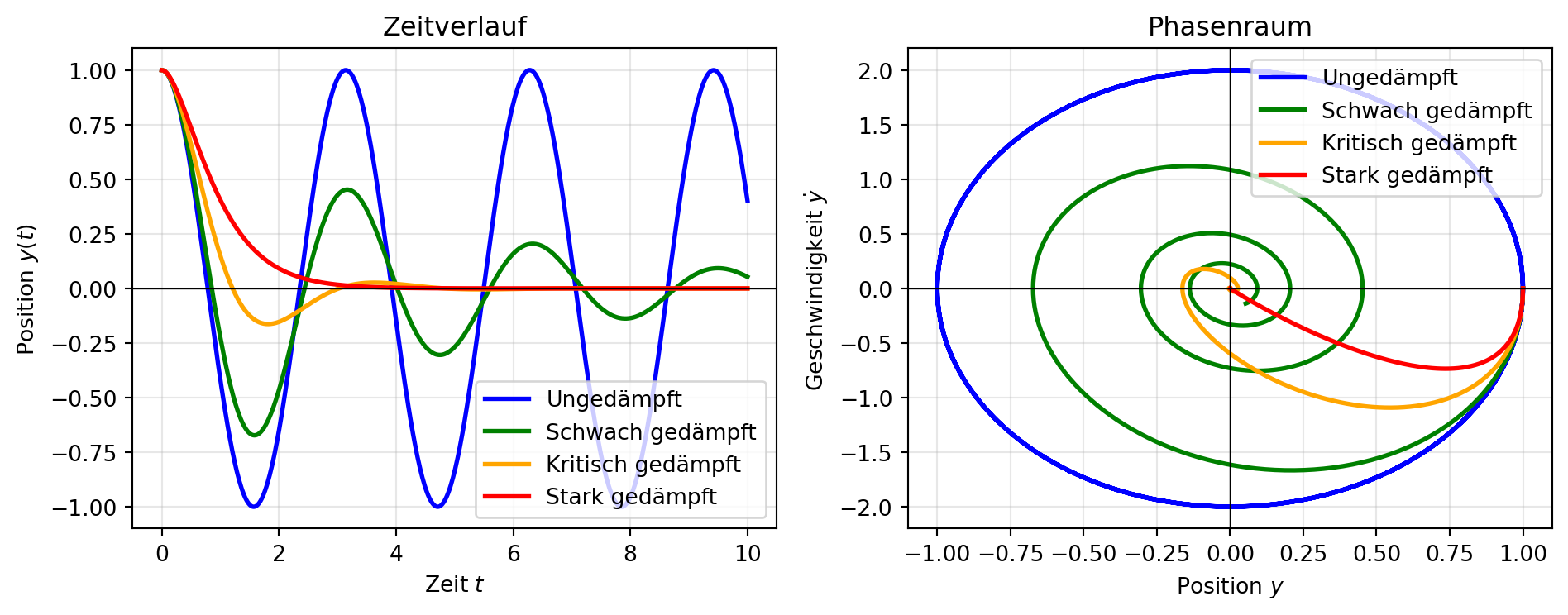
Abbildung 3: Lösung des gedämpften harmonischen Oszillators mit solve_ivp für verschiedene Dämpfungsstärken. Der Übergang vom schwingenden zum kriechenden Verhalten zeigt sich sowohl im Zeitverlauf als auch im Phasenraum.
Schwach gedämpfter Fall (c=0.5):
Anzahl der Zeitschritte: 27
Anzahl der Funktionsauswertungen: 170
Integration erfolgreich: True
Abbildung 3 zeigt das charakteristische Verhalten für verschiedene Dämpfungsstärken. Im Zeitverlauf erkennt man, wie die Schwingungsamplitude bei schwacher Dämpfung langsam abnimmt, während bei kritischer und starker Dämpfung das System ohne Überschwingen zum Gleichgewicht zurückkehrt. Im Phasenraum manifestiert sich dies als einwärts spiralende Trajektorie bei schwacher Dämpfung und als direkter Weg zum Ursprung bei überkritischer Dämpfung.
Anwendung: Die Lotka-Volterra-Gleichungen
Die Lotka-Volterra-Gleichungen beschreiben die Dynamik eines idealisierten Räuber-Beute-Systems und sind ein klassisches Beispiel für ein nichtlineares Differentialgleichungssystem: \[
\begin{aligned}
\frac{\mathrm{d}x}{\mathrm{d}t} &= \alpha x - \beta xy \\
\frac{\mathrm{d}y}{\mathrm{d}t} &= \delta xy - \gamma y
\end{aligned}
\tag{11}\]
In diesem System bezeichnet \(x\) die Beutepopulation und \(y\) die Räuberpopulation. Der Parameter \(\alpha\) beschreibt die natürliche Wachstumsrate der Beute in Abwesenheit von Räubern, \(\beta\) die Rate, mit der Räuber Beute fressen, \(\delta\) die Effizienz, mit der gefressene Beute in Räubernachwuchs umgewandelt wird, und \(\gamma\) die natürliche Sterberate der Räuber in Abwesenheit von Beute.
Code
import numpy as npimport matplotlib.pyplot as pltfrom scipy.integrate import solve_ivpdef lotka_volterra(t, z, alpha, beta, delta, gamma):""" Lotka-Volterra-Gleichungen (Räuber-Beute-Modell) Der Zustandsvektor z = [x, y] enthält die Beute- und Räuberpopulation. """ x, y = z dxdt = alpha * x - beta * x * y dydt = delta * x * y - gamma * yreturn [dxdt, dydt]# Parameteralpha =1.0# Wachstumsrate Beutebeta =0.1# Fressratedelta =0.075# Wachstumseffizienz Räubergamma =1.5# Sterberate Räuber# Anfangsbedingungen und Zeitintervallz0 = [10.0, 5.0]t_span = (0, 50)t_eval = np.linspace(0, 50, 1000)# Lösungsol = solve_ivp( lotka_volterra, t_span, z0, args=(alpha, beta, delta, gamma), method='RK45', t_eval=t_eval)fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))# Zeitverlaufax1.plot(sol.t, sol.y[0], 'b-', linewidth=2, label='Beute $x(t)$')ax1.plot(sol.t, sol.y[1], 'r-', linewidth=2, label='Räuber $y(t)$')ax1.set_xlabel('Zeit $t$')ax1.set_ylabel('Population')ax1.set_title('Populationsdynamik')ax1.legend()ax1.grid(True, alpha=0.3)# Phasenraumax2.plot(sol.y[0], sol.y[1], 'g-', linewidth=2)ax2.plot(z0[0], z0[1], 'ko', markersize=10, label='Anfang')ax2.set_xlabel('Beute $x$')ax2.set_ylabel('Räuber $y$')ax2.set_title('Phasenraum')ax2.legend()ax2.grid(True, alpha=0.3)# Gleichgewichtspunkt markierenx_eq = gamma / deltay_eq = alpha / betaax2.plot(x_eq, y_eq, 'r*', markersize=15, label=f'Gleichgewicht ({x_eq:.1f}, {y_eq:.1f})')ax2.legend()plt.tight_layout()plt.show()print(f"Anzahl der adaptiven Zeitschritte: {len(sol.t)}")print(f"Anzahl der Funktionsauswertungen: {sol.nfev}")
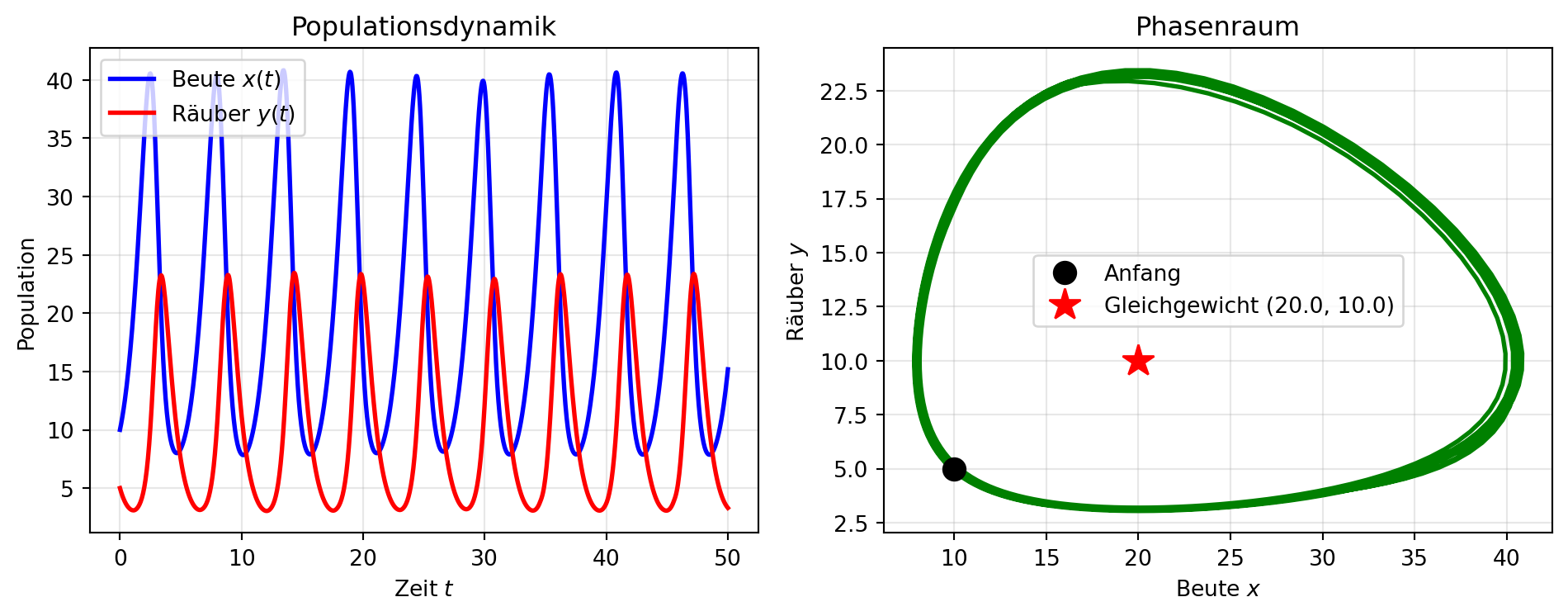
Abbildung 4: Numerische Lösung der Lotka-Volterra-Gleichungen. Die Populationen oszillieren periodisch, wobei die Räuberpopulation der Beutepopulation mit einer Phasenverschiebung folgt. Im Phasenraum zeigt sich die periodische Natur als geschlossene Kurve um den Gleichgewichtspunkt.
Anzahl der adaptiven Zeitschritte: 1000
Anzahl der Funktionsauswertungen: 554
Abbildung 4 zeigt die charakteristische Dynamik des Räuber-Beute-Systems. Im Zeitverlauf oszillieren beide Populationen periodisch, wobei die Maxima der Räuberpopulation den Maxima der Beutepopulation zeitversetzt folgen. Diese Phasenverschiebung hat eine intuitive Interpretation: Wenn viel Beute vorhanden ist, vermehren sich die Räuber, was zu einem Anstieg der Räuberpopulation führt. Die wachsende Räuberzahl dezimiert die Beute, woraufhin auch die Räuber aufgrund von Nahrungsmangel abnehmen. Mit weniger Räubern kann sich die Beute wieder erholen, und der Zyklus beginnt von neuem.
Im Phasenraum manifestiert sich diese periodische Dynamik als geschlossene Kurve um den Gleichgewichtspunkt. Die Tatsache, dass die Kurve geschlossen ist, zeigt die periodische Natur der Lösung. Das Gleichgewicht selbst ist instabil und wird nie erreicht; stattdessen führt jede Abweichung davon zu den beobachteten Oszillationen.
Zusammenfassung
Die Runge-Kutta-Verfahren bilden eine Familie von Integrationsverfahren, die durch Verwendung mehrerer Funktionsauswertungen pro Zeitschritt eine höhere Genauigkeit erreichen als das einfache Euler-Verfahren. Das Euler-Verfahren selbst kann als Runge-Kutta-Verfahren erster Ordnung betrachtet werden.
Das Heun-Verfahren oder Runge-Kutta-Verfahren zweiter Ordnung verwendet eine Prädiktor-Korrektor-Strategie mit zwei Funktionsauswertungen und erreicht quadratische Konvergenz. Das klassische Runge-Kutta-Verfahren vierter Ordnung kombiniert vier Steigungsschätzungen nach dem Prinzip der Simpson-Regel und erzielt bei moderatem Mehraufwand eine dramatisch bessere Genauigkeit.
Die Funktion scipy.integrate.solve_ivp bietet eine robuste Implementierung dieser Verfahren mit automatischer Schrittweitenkontrolle. Die Standardmethode RK45 ist für die meisten Anwendungen geeignet und kombiniert gute Genauigkeit mit adaptiver Zeitschrittsteuerung.
Tip
Für die meisten praktischen Anwendungen ist solve_ivp mit der Standardmethode RK45 eine ausgezeichnete Wahl. Die automatische Schrittweitenkontrolle sorgt für Effizienz und Zuverlässigkeit, und die Konvergenzordnung 4 ermöglicht hohe Genauigkeit bei moderatem Rechenaufwand.
Im nächsten Kapitel werden wir die automatische Zeitschrittkontrolle genauer untersuchen, die das zentrale Feature moderner Differentialgleichungslöser darstellt und solve_ivp so robust macht.